摘要:KafkaProducer在发送消息的时候,需要指定发送到哪个分区, 那么这个分区策略都有哪些呢?
本文分享自华为云社区《Kafka生产者3中分区分配策略》,作者:石臻臻的杂货铺。
KafkaProducer在发送消息的时候,需要指定发送到哪个分区, 那么这个分区策略都有哪些呢?我们今天来看一下
使用分区策略的配置:

1. DefaultPartitioner 默认分区策略
全路径类名:org.apache.kafka.clients.producer.internals.DefaultPartitioner
- 如果消息中指定了分区,则使用它
- 如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
- 如果不存在分区或key,则会使用粘性分区策略,关于粘性分区请参阅 KIP-480。
粘性分区Sticky Partitioner
为什么会有粘性分区的概念?
首先,我们指定,Producer在发送消息的时候,会将消息放到一个ProducerBatch中, 这个Batch可能包含多条消息,然后再将Batch打包发送。关于这一块可以看看我之前的文章 图解Kafka Producer 消息缓存模型。
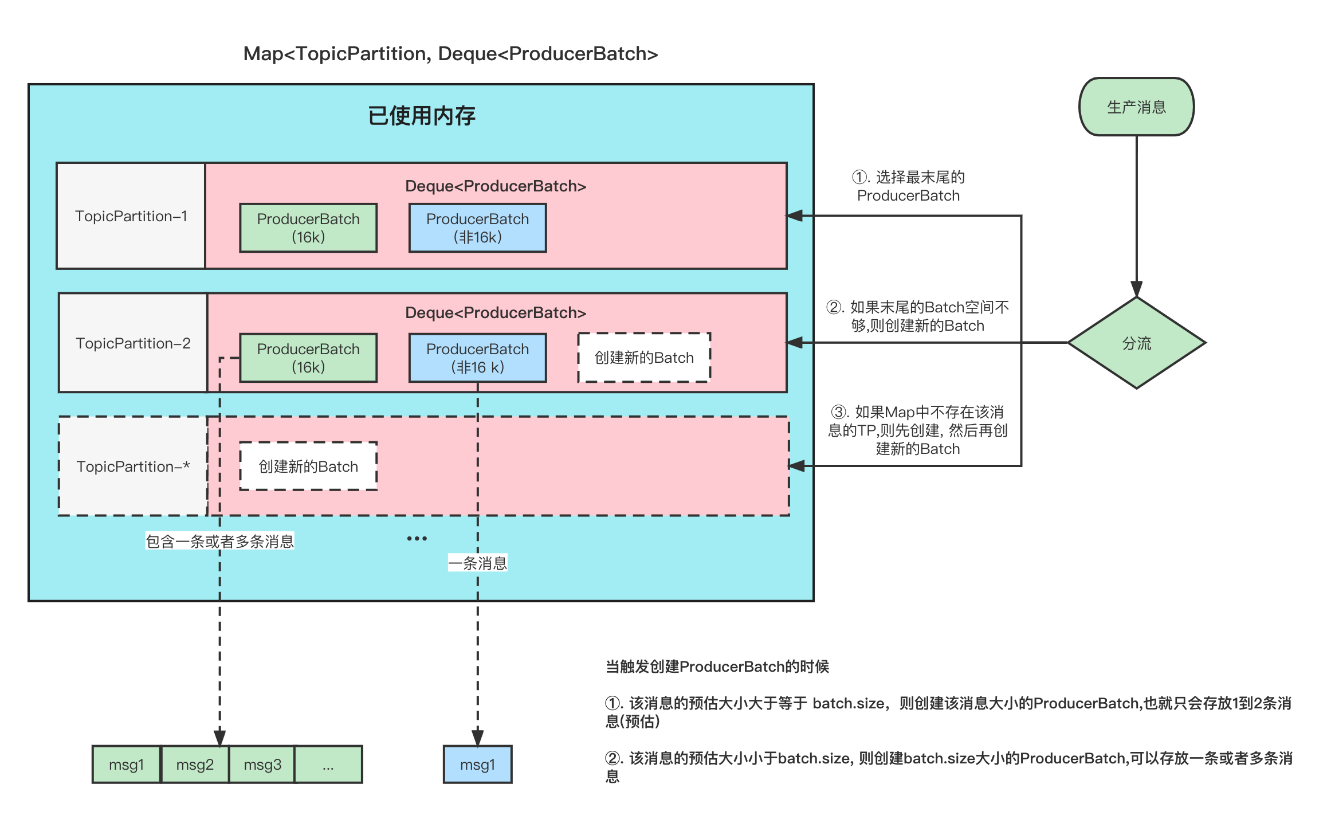
这样做的好处就是能够提高吞吐量,减少发起请求的次数。
但是有一个问题就是, 因为消息的发送它必须要你的一个Batch满了或者linger.ms时间到了,才会发送。如果生产的消息比较少的话,迟迟难以让Batch塞满,那么就意味着更高的延迟。
在之前的消息发送中,就将消息轮询到各个分区的, 本来消息就少,你还给所有分区遍历的分配,那么每个ProducerBatch都很难满足条件。
那么假如我先让一个ProducerBatch塞满了之后,再给其他的分区分配是不是可以降低这个延迟呢?
详细的可以看看下面这张图
这张图的前提是:
Topic1 有3分区, 此时给Topic1 发9条无key的消息, 这9条消息加起来都不超过batch.size .
那么以前的分配方式和粘性分区的分配方式如下
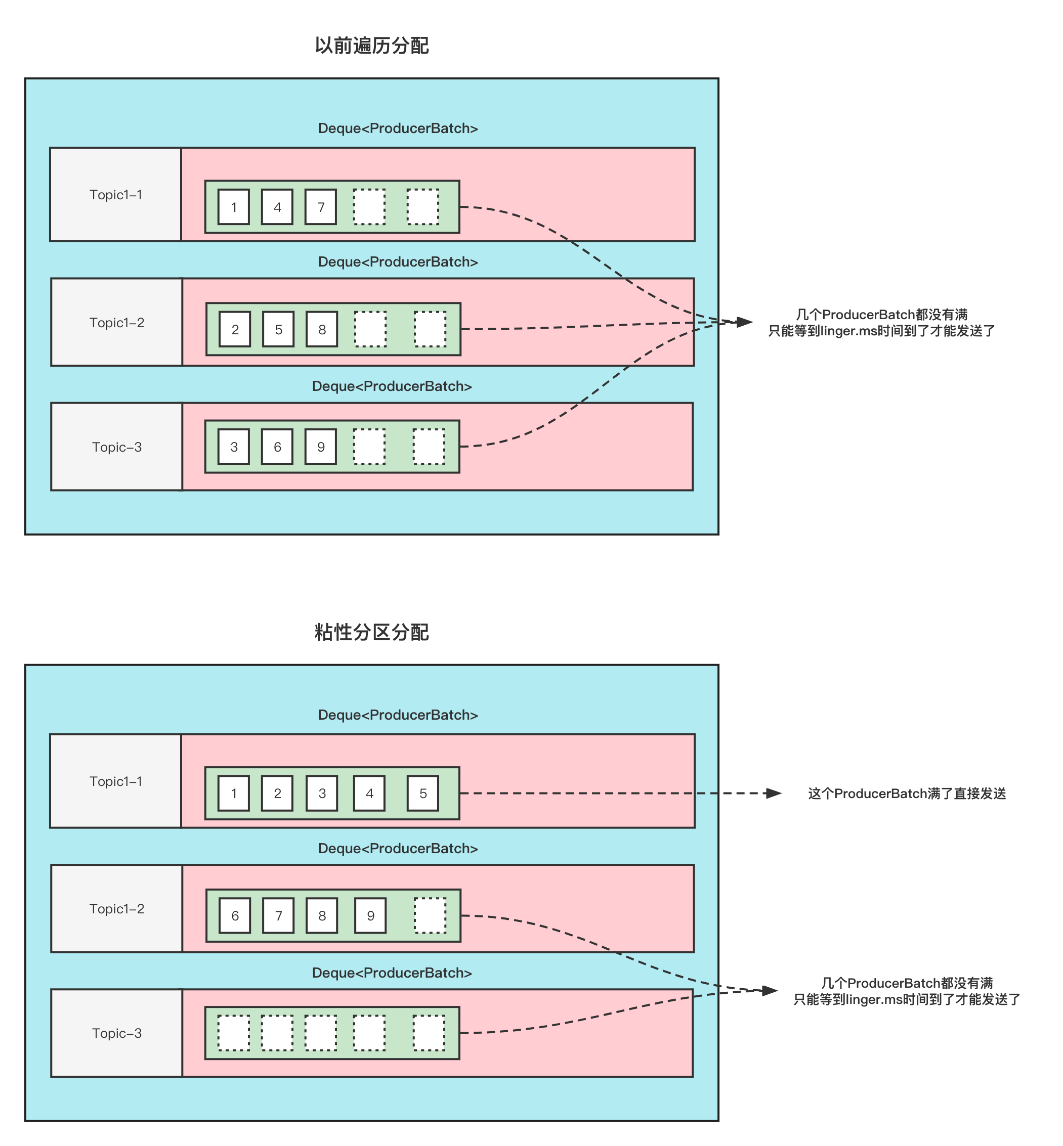
可以看到,使用粘性分区之后,至少是先把一个Batch填满了发送然后再去填充另一个Batch。不至于向之前那样,虽然平均分配了,但是导致一个Batch都没有放满,不能立即发送。这不就增大了延迟了吗(只能通过linger.ms时间到了才发送)
划重点:
- 当一个Batch发送之后,需要选择一个新的粘性分区的时候
①. 可用分区<1 ;那么选择分区的逻辑是在所有分区中随机选择。
②. 可用分区=1; 那么直接选择这个分区。
③. 可用分区>1 ; 那么在所有可用分区中随机选择。 - 当选择下一个粘性分区的时候,不是按照分区平均的原则来分配。而是随机原则(当然不能跟上一次的分区相同)
例如刚刚发送到的Batch是 1号分区,等Batch满了,发送之后,新的消息可能会发到2或者3, 如果选择的是2,等2的Batch满了之后,下一次选择的Batch仍旧可能是1,而不是说为了平均,选择3分区。
2.UniformStickyPartitioner 纯粹的粘性分区策略
全路径类名:org.apache.kafka.clients.producer.internals.UniformStickyPartitioner
他跟DefaultPartitioner 分区策略的唯一区别就是。
DefaultPartitionerd 如果有key的话,那么它是按照key来决定分区的,这个时候并不会使用粘性分区
UniformStickyPartitioner 是不管你有没有key, 统一都用粘性分区来分配。
3. RoundRobinPartitioner 分区策略
全路径类名:org.apache.kafka.clients.producer.internals.RoundRobinPartitioner
- 如果消息中指定了分区,则使用它
- 将消息平均的分配到每个分区中。
- 与key无关
@Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); int nextValue = nextValue(topic); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (!availablePartitions.isEmpty()) { int part = Utils.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { // no partitions are available, give a non-available partition return Utils.toPositive(nextValue) % numPartitions; } }
上面是具体代码。有个地方需要注意;
- 当可用分区是0的话,那么就是遍历的是所有分区中的。
- 当有可用分区的话,那么遍历的是所有可用分区的。